This is the third in a series of database design case studies. This database consists of three tables. It is recommended to begin with the first case study, which illustrates a two-table database.
Your marketing research firm has been engaged by a major food supplier to aid them in analyzing cereal breakfast food sales.
Certain attributes of the cereals and the stores in which they are sold are of special interest to the client.
Cereals:
Stores:
Having concluded the system analysis phase, your firm is ready to begin gathering data. You have been asked to come up with a preliminary design for a relational database design.
Prepare a diagram of the database including tables, fields, relationships, and primary and foreign keys.
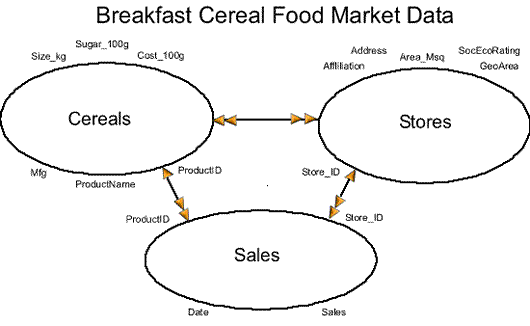
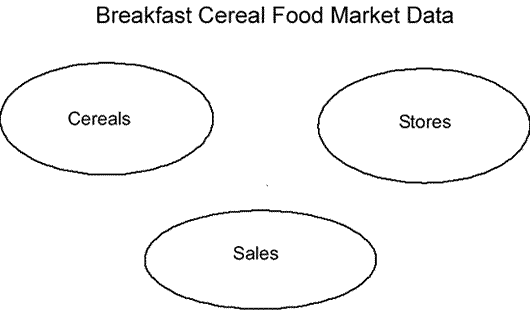
The first step in database design is to determine all the necessary fields and segregate them into groups that mirror the natural order of the real world. In this case we have Cereals, Stores, and Sales.

When the fields have been grouped into their natural order, each group represents a table.
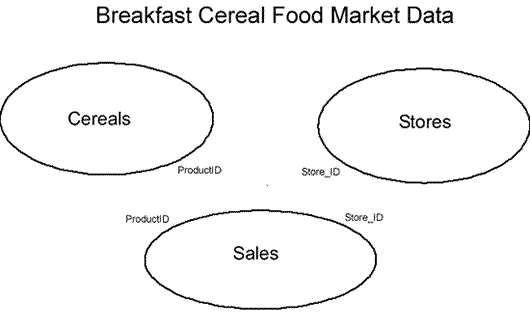
Each record in a table must be uniquely identified by its value in the table's key field.
The next step is to identify the relationships between the tables. In this case we have a many-to-many relationship between Cereals and Stores. That is to say that Cereals may be sold in many stores, and Stores sell many Cereals.
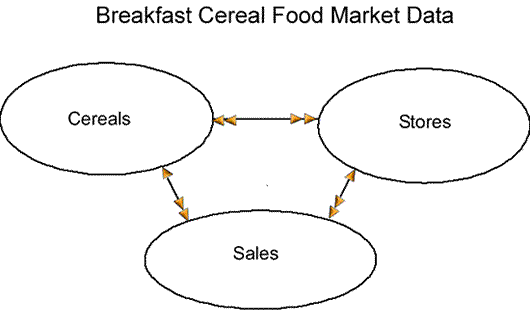
When two tables have a many-to-many relationship we create a third table, often referred to as a lien table because it completes the many-to-many relationship.
Notice that the relationship between both many-to-many tables and the lien is a one-to-many relationship.
As with all one-to-many relationships, we place values from the "one" table's key field into a field of the related records in the "many" table. So in this example the primary keys from both "one" tables (Cereals and Stores) are secreted into the "many" table (Sales) as foreign keys.
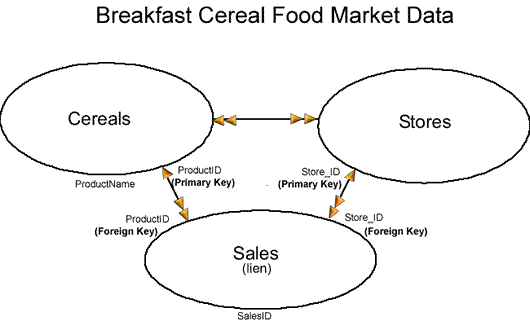
The final result is a relational database model. When a database model satisfies all the technical requirements it is said to be rationalized.
The objective of rationalizing a database structure is to eliminate redundancy in order to save disk space and to simplify updates by insuring that every piece of information exists in only one place. The only fields that repeat are the foreign keys.
Every rational database model must obey these four rules and pass these three tests.